
A modern application of data-engineering and data-science on public Hockey (NHL) data for the purposes of learning & development
Table of contents
Introduction
The motivation behind this project was simple: make public hockey data available using modern technologies for the purposes of data-science & data-visualization. We wanted to be able to answer questions like…
- Which players are most likely to have a breakout season next year?
- Which draft prospects are most likely to succeed in the NHL?
- How many goals should we expect from elite players like Connor McDavid or Auston Matthews next season?
- Where on the ice are individual players most efficient with their shooting?
Architecture
In order to get to this state of-course, a lot of data-engineering was necessary. Below is a visual representation of the project architecture.
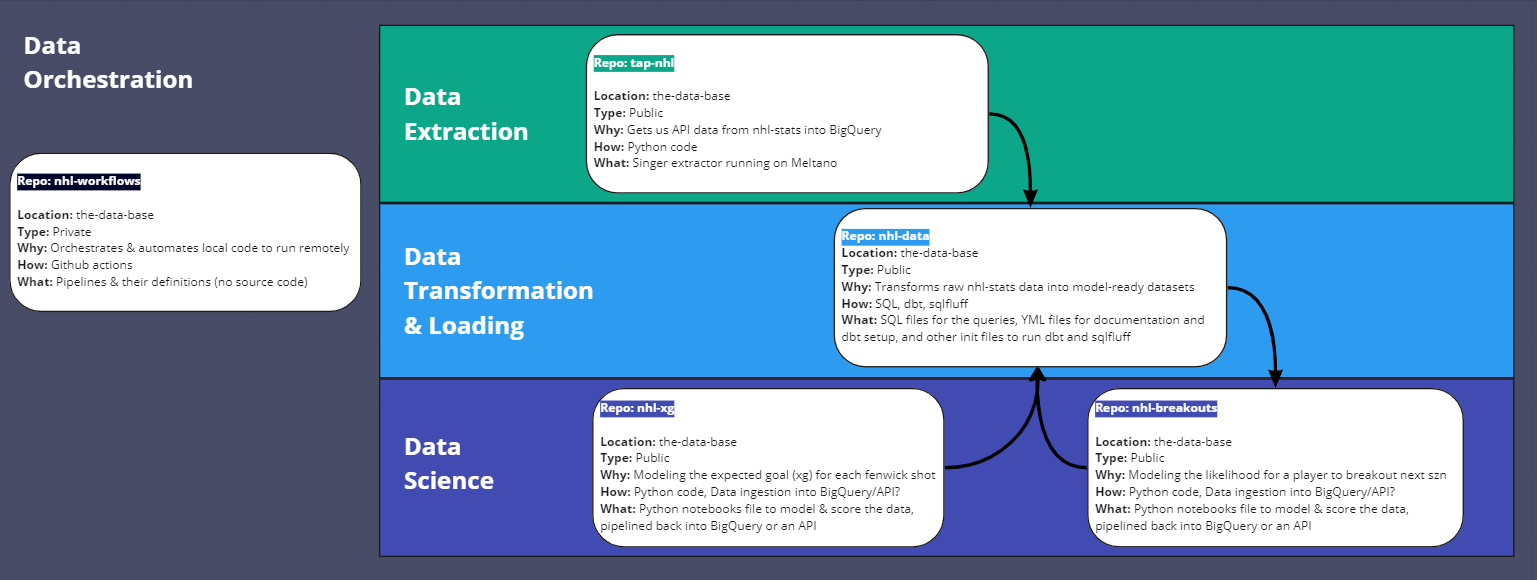
Data extraction
Currently, we only have a single source of data: the NHL Stats API. The Github repo that we built to extract the data is called tap-nhl. It is a Singer tap for the NHL Stats API.
Built with the Meltano Tap SDK for Singer Taps.
Below is a flow diagram explaining how it works:
flowchart TD
Root[NHL Stats API] -->|Year| Seasons[Seasons]
Root[NHL Stats API] --> Conferences[Conferences]
Root[NHL Stats API] --> Divisions[Divisions]
Root[NHL Stats API] -->|Year| Draft[Draft]
Seasons[Seasons] -->|Season| Schedule[Schedule]
Seasons[Seasons] --> |Season| Teams[Teams]
Schedule[Schedule] -->|Game PK| Shifts[Shifts]
Schedule[Schedule] -->|Game PK| Game[Game]
Game[Game] -->|Game PK| Plays[Live Feed Plays]
Game[Game] -->|Game PK| Linescore[Live Feed Linescore]
Game[Game] -->|Game PK| Boxscore[Live Feed Boxscore]
Teams[Teams] --> |Roster| Player[Players]
Draft[Draft] -->|Prospect ID| Prospects[Prospects]
Resources
- Repo: tap-nhl
Data transformation & loading
All of this work is contained within a Github repo called nhl-data and uses dbt to model our raw data. It contains the source code used to transform raw nhl data from the NHL Stats API into analysis-ready models.
In other words, this is where the SQL magic happens using dbt. Ultimately, this work converts confusing raw data into:
- Data analyst/scientist friendly datasets all within one data warehouse (BigQuery)
- Well-documented tables, field definitions, and queries
- Reliable data that is tested and validated before ever making it into production
Resources
- Repo: nhl-data
- Documentation: dbt generated documentation
Data science
Consider this section separate from the rest. Each question that we decide to answer of our newly modeled data will live in this bucket. For example, one of the projects that spawned from this was the nhl-xg project
How to access our datasets
If you would like to access our BigQuery datasets for your own analytical use, please reach out via Slack!
Please note that you’ll be required to sign up for Google Cloud Platform in order to run queries against our dataset from within your own project.
To access the shared datasets, our project admins will add your Google account to our dataset as the role BigQuery Data Viewer.
Then, within your own BigQuery console, click + Add Data at the top of the Explorer navigation pane, then Star a project by name and type in the name nhl-breakouts. You will then see the newly starred project and the datasets to which you have been granted view access.
Happy modeling!